Views: 5,416
ChatGPT web interface VS Using OpenAI API
Most of you probably know that the University has provided the HKUST ChatGPT Platform for all the HKUST students, faculty members and staff. While the ChatGPT web interface offers a user-friendly experience and allows users to interact with large language models (LLMs) through a convenient conversational way (in form of chatbot), do you know using OpenAI API key can even take the utilization of LLMs to a whole new level of power and possibilities? If you haven’t given it a try yet, follow our guide below and unlock its potential!
Benefits of using API instead of ChatGPT web interface
👍 Handle text larger than limits
One significant advantage of using the OpenAI API key is the ability to handle text that exceeds the model’s token limits. The ChatGPT interface has inherent restrictions on input length. In contrast, by using the API key, you can split long text into smaller chunks and seamlessly process them individually. This allows you to work with large documents that surpasses the ChatGPT interface’s limitations.
👍 Loop repetitive process
The ChatGPT interface primarily focuses on interactive conversations, making it less suitable for automating repetitive processes. However, with the API key, we can use functions like for loop to iterate over tasks, thus streamlining and automating repetitive operations. This feature enhances productivity and enables the efficient execution of batch tasks, such as generating multiple responses or analyzing large datasets.
👍 Flexible output storage
You can store the LLMs response output in various formats, such as dataframes, JSON, CSV, and more. This flexibility allows for seamless integration with other tools and systems. By receiving outputs in structured formats, you can easily process and manipulate the data further, perform analysis, or integrate it into existing pipelines.
👍 Integration with other models and frameworks
You can also seamlessly integrate OpenAI models with other powerful tools, libraries, and frameworks relevant to your use case, such as LangChain, LlamaIndex, etc. This opens up a world of possibilities, enabling you to leverage the strengths of different models and combine them to create more sophisticated and comprehensive solutions.
What you will learn in this article
- Get your own OpenAI API key from HKUST API Developer Portal
- Use your OpenAI API key in Python
- Some possible use cases (with sample code):
- Name Entity Recognition (NER): Identify and extract named entities from text, such as names of people, locations, etc.
- Sentiment Classification: Analyze the sentiment of text to determine whether it is positive, negative, or neutral.
- Semantic Search: Extract the semantic meaning from text, enabling deeper understanding and interpretation of the underlying concepts.
- Language Translation: Translate different linguistic styles, such as classical Chinese (文言文) to vernacular Chinese (白話文).
Prerequisite: Basic understanding of Python
You don’t necessarily need to be highly proficient in Python, but it is important to have the ability to “read” Python code and comprehend its meaning and functionality.
If you’re completely new to Python, we recommend you checking out our “Learn Python From Zero For Absolute Beginner” series, where you can gain some foundational knowledge to help you along the way.
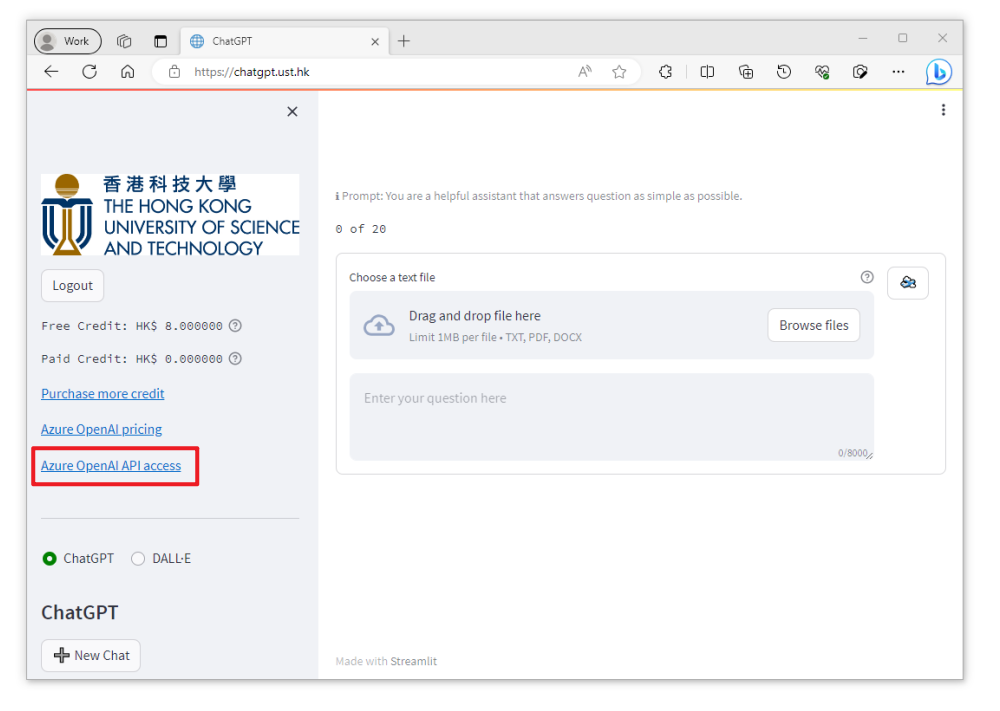
Get your own OpenAI API key for free
Our university provides Azure OpenAI API Service. All HKUST staff and students have a monthly free credit of HKD$8. The credits are shared with the usage of HKUST ChatGPT platform. For additional usage, it is available for top-up credit at your own cost.
Please note that the service description above is based on the information on the ITSO’s website as of 16 Nov 2023, and is subject to potential future revisions or updates.
Steps
1. Sign in/sign up in the HKUST API Developer Portal using your HKUST account.
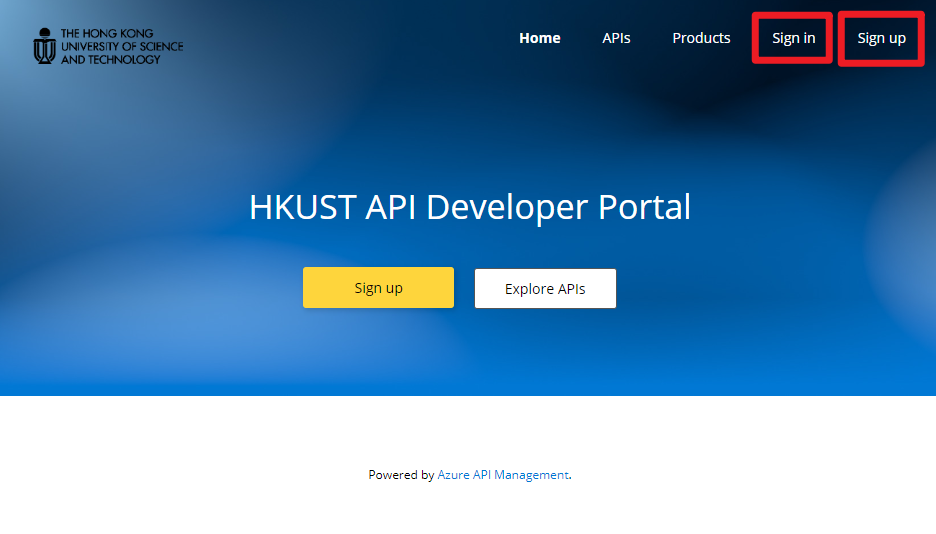
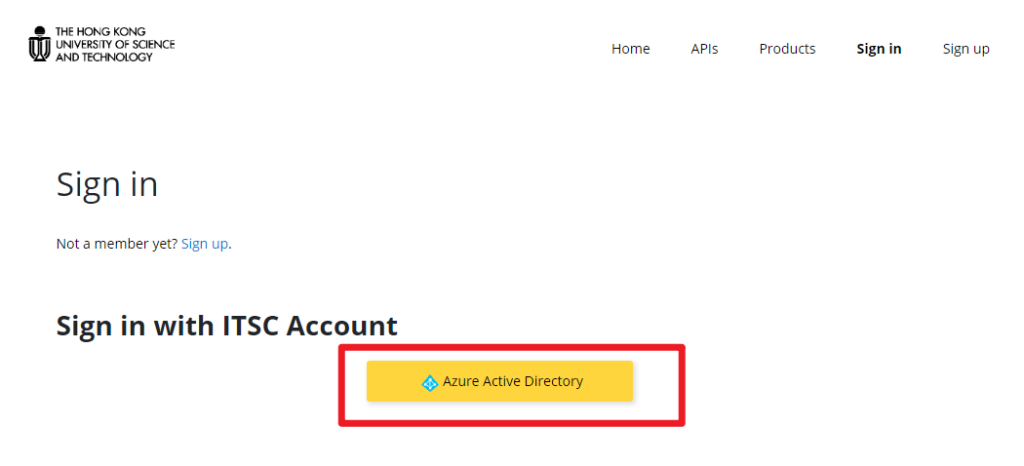
2. Click “Products” in the menu bar.
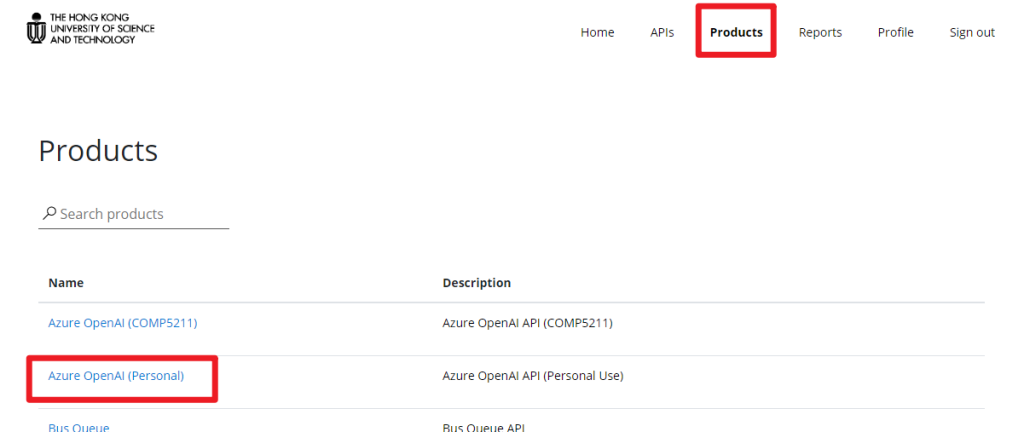
3. Click “Azure OpenAI (Personal)” in the product list.
https://hkust.developer.azure-api.net/products
4. Enter a name for the product subscription and click “Subscribe“.
In the example as shown in the screenshot, we entered “OpenAI for work” as our product subscription name.
https://hkust.developer.azure-api.net/product#product=azure-openai-personal
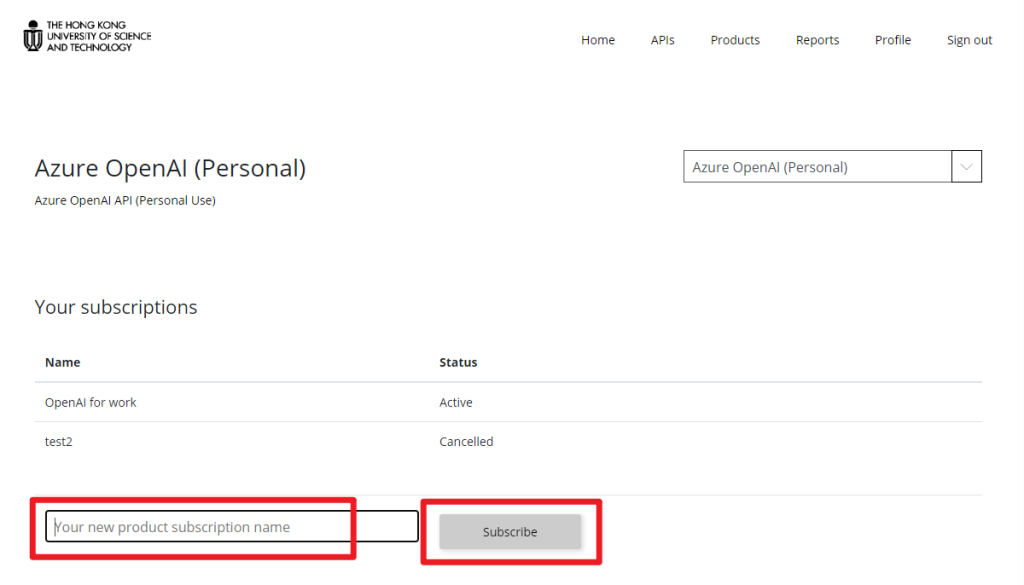
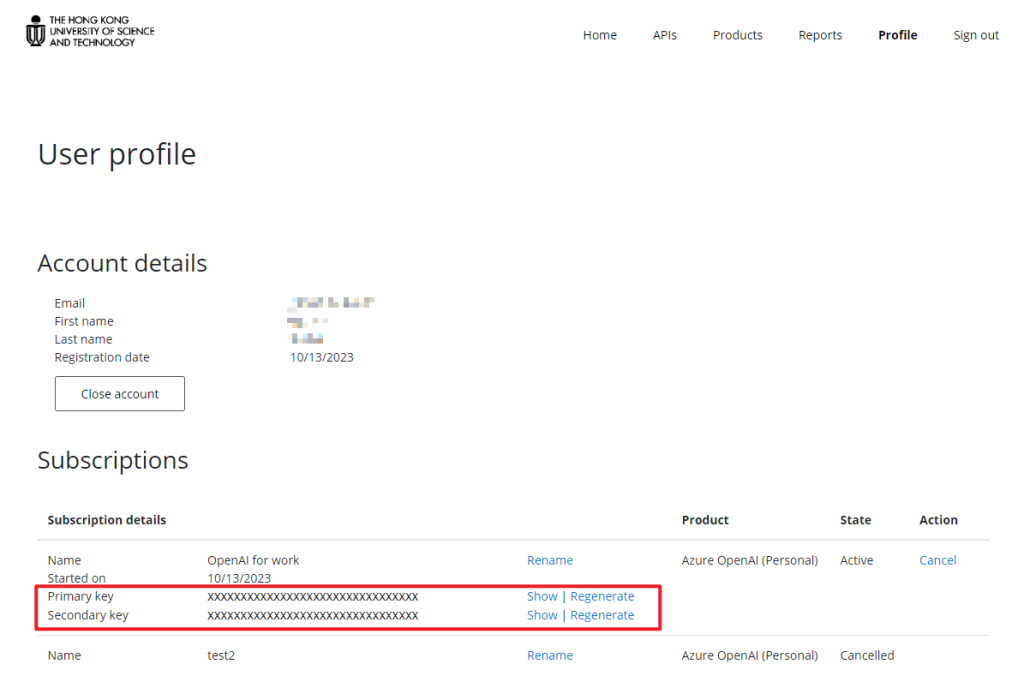
5. Click “Profile” in the menu bar.
6. In the “Subscriptions” section, you will see a primary key and a secondary key for the “Azure OpenAI (Personal)” Product.
7. Click “Show” and copy the key.
Congratulations! You now get your own OpenAI API key. Let’s follow our samples below to see how you could utilize it!
https://hkust.developer.azure-api.net/profile
Use your OpenAI API key in Python
Last week (on 6 Nov 2023), a new version of OpenAI is released. It is important to note that the code of the OpenAI Python API library differs between the previous version 0.28.1 and the new version 1.x, which is a breaking change upgrade. In the following section, we will show the code snippets for both versions.
While the newly released GPT-4 Turbo model undoubtedly offers enhanced capabilities and power, we have chosen to utilize the gpt-35-turbo model for demonstration here. Rest assured, even though it is a slightly older version, it still delivers impressive performance and serves our demonstration needs.
We encourage you to explore the potential of GPT-4 Turbo by yourself once Azure OpenAI support it.
The OpenAI API is powered by a diverse set of models with different capabilities and price points. Please see below for details:
- Details of different models: https://platform.openai.com/docs/models
- Pricing details (per 1,000 tokens) (default: USD$) : https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/

Without further ado, let’s get started!
Go to line 9 of the code snippets below, replace <your openai api key> with your API key that obtained from the HKUST API Developer Portal (either the primary key or secondary key is okay).
previous version 0.28.1
# Install and import OpenAI Python library
!pip install openai==0.28.1
import openai
# Parameters
openai.api_type = "azure"
openai.api_base = "https://hkust.azure-api.net"
openai.api_version = "2023-05-15"
openai.api_key = "<your openai api key>" #put your api key here
# Function
def get_response(message, instruction):
response = openai.ChatCompletion.create(
engine = 'gpt-35-turbo',
temperature = 1,
messages = [
{"role": "system", "content": instruction},
{"role": "user", "content": message}
]
)
# print token usage
print(response.usage)
# return the response
return response.choices[0]["message"]["content"]new version 1.x
# Install and import OpenAI Python library
!pip install openai --upgrade
from openai import AzureOpenAI
# Parameters
client = AzureOpenAI(
azure_endpoint = "https://hkust.azure-api.net",
api_version = "2023-05-15",
api_key = "<your openai api key>" #put your api key here
)
# Function
def get_response(message, instruction):
response = client.chat.completions.create(
model = 'gpt-35-turbo',
temperature = 1,
messages = [
{"role": "system", "content": instruction},
{"role": "user", "content": message}
]
)
# print token usage
print(response.usage)
# return the response
return response.choices[0].message.contentResult output
By inputting your prompt in get_response(), you can get the answer.
get_response("Who are you?", "You are an assistant that speaks like Shakespeare.")
Explanation
| Terms | Explanation |
|---|---|
| temperature | The temperature parameter controls the randomness of the text generated by GPT. A higher temperature value (e.g. 1) makes the output more random and creative, while a lower value (e.g. 0.2) makes it less random but more relevant to the given context. If you are interested in knowing more about the algorithm behind, you can refer to this link, which offers a good explanation of the temperature parameter: https://ai.stackexchange.com/questions/32477/what-is-the-temperature-in-the-gpt-models |
| “role”: “system” | System messages can be used to provide instructions or set the behavior of the assistant. In the example above, we instructed the system to speak like Shakespere. |
| “role”: “user” | User messages represent the input or query from the user. |
References
Microsoft Learn. (2023, November 11). How to migrate to OpenAI Python v1.x. Azure OpenAI Service. https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/migration
Shieh, J. (2023, November 6). Best practices for prompt engineering with OpenAI API. OpenAI Help Center. https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
Use cases (with sample code)
The get_response() function created above allows you to use natural language (i.e. everyday language) to ask questions and perform various tasks. With Python, you can now create more complex and customized tasks that fit your specific needs. Below are some possible use cases.
All the codes below are shared in our GitHub. Please feel free to download the whole notebook for reference.
Please note that the answers generated by GPT are not guaranteed to be 100% accurate. While GPT is a powerful language model trained on a vast amount of data, it can still produce incorrect or misleading information. The model generates responses based on patterns and associations found in the training data, but it does not possess real-time fact-checking capabilities. Therefore, it is always advisable to verify the information obtained from the model through reliable and authoritative sources. Critical thinking and cross-referencing with multiple sources are essential to ensure the accuracy and reliability of the information obtained.
Additionally, fine-tuning and prompt engineering are often necessary to improve the LLMs’ performance and align their responses with specific requirements. These models can serve as powerful tools, but they still require careful tuning and prompt design to ensure accuracy and reliability in their outputs.
Name Entity Recognition (NER)
Name Entity Recognition (NER) is the process of identifying and extracting named entities from text, such as names of people, locations, etc. To illustrate its application, let’s use the text in this webpage as sample data: https://library.hkust.edu.hk/events/conferences/ai-scholarly-commu-2023/
The Library is organizing a Researchers’ Series Symposium. The webpage above contains the information of the speakers and their presentation. Let’s use LLMs to extract only the speaker name, their affiliated University, expertise, and presentation title.
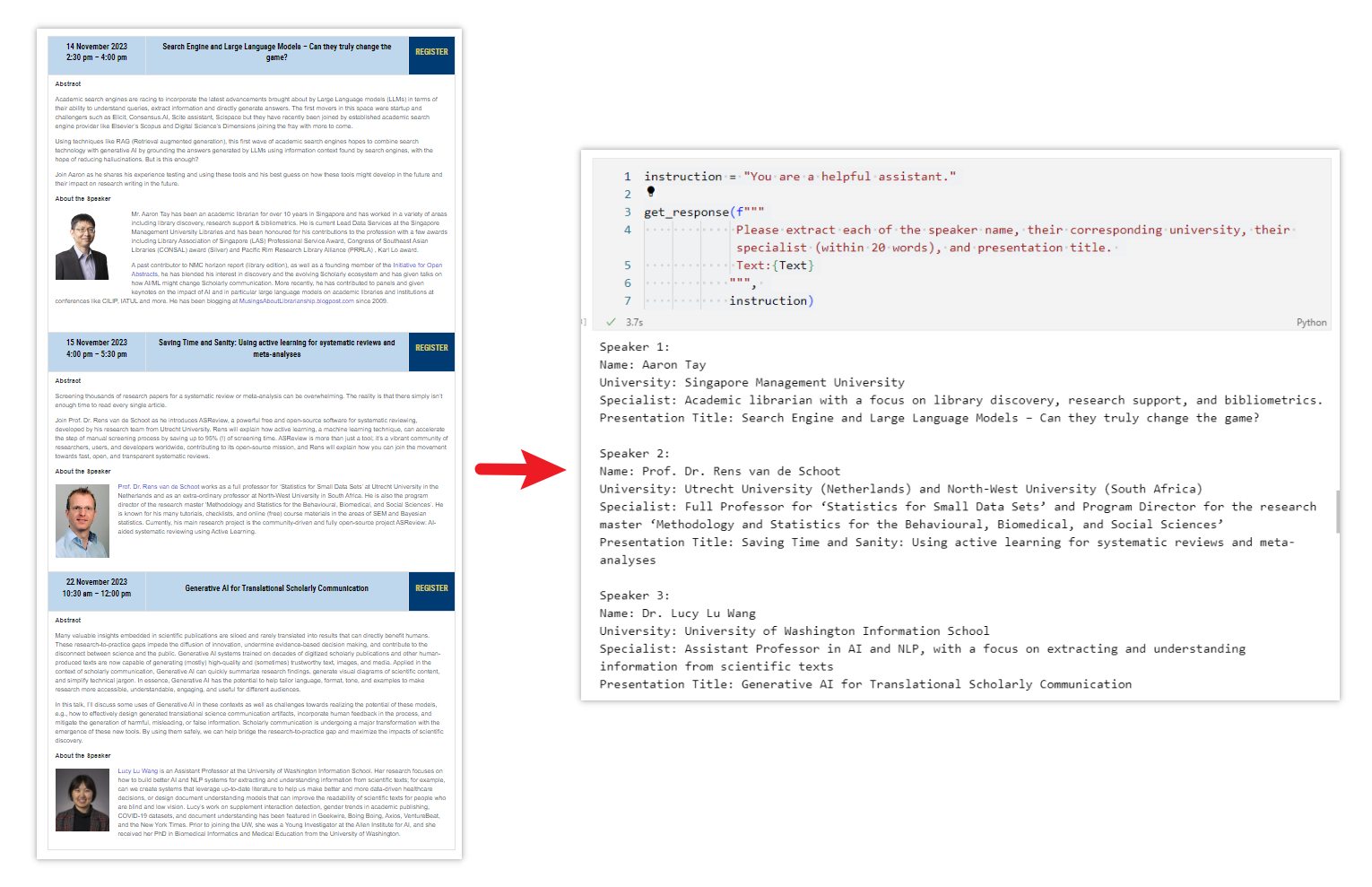
First, simply copy all the text from the webpage. Put them in a variable (a variable named text in the example below).
# Text copied from https://library.hkust.edu.hk/events/conferences/ai-scholarly-commu-2023/ Text = """ 14 November 2023 2:30 pm – 4:00 pm Search Engine and Large Language Models – Can they truly change the game? REGISTER Abstract Academic search engines are racing to incorporate the latest advancements brought about by Large Language models (LLMs) in terms of their ability to understand queries, extract information and directly generate answers. The first movers in this space were startup and challengers such as Elicit, Consensus.AI, Scite assistant, Scispace but they have recently been joined by established academic search engine provider like Elsevier's Scopus and Digital Science's Dimensions joining the fray with more to come. Using techniques like RAG (Retrieval augmented generation), this first wave of academic search engines hopes to combine search technology with generative AI by grounding the answers generated by LLMs using information context found by search engines, with the hope of reducing hallucinations. But is this enough? Join Aaron as he shares his experience testing and using these tools and his best guess on how these tools might develop in the future and their impact on research writing in the future. About the Speaker Aaron TayMr. Aaron Tay has been an academic librarian for over 10 years in Singapore and has worked in a variety of areas including library discovery, research support & bibliometrics. He is current Lead Data Services at the Singapore Management University Libraries and has been honoured for his contributions to the profession with a few awards including Library Association of Singapore (LAS) Professional Service Award, Congress of Southeast Asian Libraries (CONSAL) award (Silver) and Pacific Rim Research Library Alliance (PRRLA) , Karl Lo award. A past contributor to NMC horizon report (library edition), as well as a founding member of the Initiative for Open Abstracts, he has blended his interest in discovery and the evolving Scholarly ecosystem and has given talks on how AI/ML might change Scholarly communication. More recently, he has contributed to panels and given keynotes on the impact of AI and in particular large language models on academic libraries and institutions at conferences like CILIP, IATUL and more. He has been blogging at MusingsAboutLibrarianship.blogpost.com since 2009. 15 November 2023 4:00 pm – 5:30 pm Saving Time and Sanity: Using active learning for systematic reviews and meta-analyses REGISTER Abstract Screening thousands of research papers for a systematic review or meta-analysis can be overwhelming. The reality is that there simply isn't enough time to read every single article. Join Prof. Dr. Rens van de Schoot as he introduces ASReview, a powerful free and open-source software for systematic reviewing, developed by his research team from Utrecht University. Rens will explain how active learning, a machine learning technique, can accelerate the step of manual screening process by saving up to 95% (!) of screening time. ASReview is more than just a tool; it's a vibrant community of researchers, users, and developers worldwide, contributing to its open-source mission, and Rens will explain how you can join the movement towards fast, open, and transparent systematic reviews. About the Speaker prof rens van de schoot profile photoProf. Dr. Rens van de Schoot works as a full professor for 'Statistics for Small Data Sets' at Utrecht University in the Netherlands and as an extra-ordinary professor at North-West University in South Africa. He is also the program director of the research master 'Methodology and Statistics for the Behavioural, Biomedical, and Social Sciences'. He is known for his many tutorials, checklists, and online (free) course materials in the areas of SEM and Bayesian statistics. Currently, his main research project is the community-driven and fully open-source project ASReview: AI-aided systematic reviewing using Active Learning. 22 November 2023 10:30 am – 12:00 pm Generative AI for Translational Scholarly Communication REGISTER Abstract Many valuable insights embedded in scientific publications are siloed and rarely translated into results that can directly benefit humans. These research-to-practice gaps impede the diffusion of innovation, undermine evidence-based decision making, and contribute to the disconnect between science and the public. Generative AI systems trained on decades of digitized scholarly publications and other human-produced texts are now capable of generating (mostly) high-quality and (sometimes) trustworthy text, images, and media. Applied in the context of scholarly communication, Generative AI can quickly summarize research findings, generate visual diagrams of scientific content, and simplify technical jargon. In essence, Generative AI has the potential to help tailor language, format, tone, and examples to make research more accessible, understandable, engaging, and useful for different audiences. In this talk, I'll discuss some uses of Generative AI in these contexts as well as challenges towards realizing the potential of these models, e.g., how to effectively design generated translational science communication artifacts, incorporate human feedback in the process, and mitigate the generation of harmful, misleading, or false information. Scholarly communication is undergoing a major transformation with the emergence of these new tools. By using them safely, we can help bridge the research-to-practice gap and maximize the impacts of scientific discovery. About the Speaker Dr Lucy Lu Wang profile photoLucy Lu Wang is an Assistant Professor at the University of Washington Information School. Her research focuses on how to build better AI and NLP systems for extracting and understanding information from scientific texts; for example, can we create systems that leverage up-to-date literature to help us make better and more data-driven healthcare decisions, or design document understanding models that can improve the readability of scientific texts for people who are blind and low vision. Lucy's work on supplement interaction detection, gender trends in academic publishing, COVID-19 datasets, and document understanding has been featured in Geekwire, Boing Boing, Axios, VentureBeat, and the New York Times. Prior to joining the UW, she was a Young Investigator at the Allen Institute for AI, and she received her PhD in Biomedical Informatics and Medical Education from the University of Washington. """
Then, use the get_response() function we created above. You can then get the results in seconds!
instruction = "You are a helpful assistant."
get_response(f"""
Please extract each of the speaker name, their corresponding university, their specialist (within 20 words), and presentation title.
Text:{Text}
""",
instruction)Output:
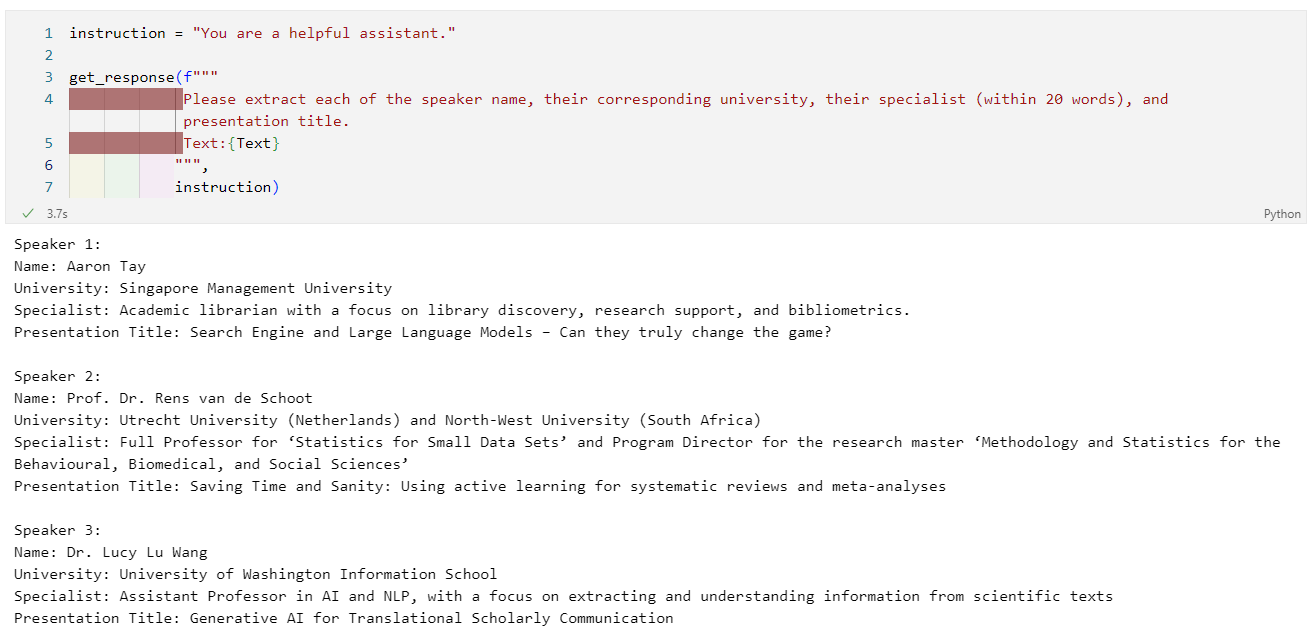
We may also ask LLMs to return the response in a particular format such as CSV and JSON. In this example, we add Please return the results in csv format in the prompt.
instruction = "You are a helpful assistant."
csv_result = get_response(f"""
Please extract each of the speaker name, their corresponding university, their specialist (within 20 words), and presentation title. Please return the results in csv format.
Text:{Text}
""",
instruction)Output:
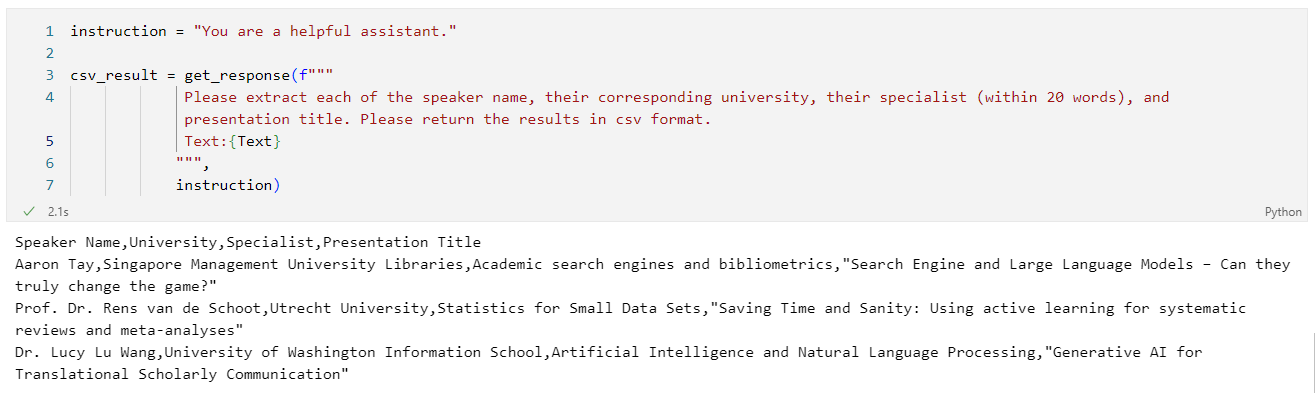
The results can then be exported to a csv file.
# save the result to csv file
import csv
with open('outputfile_NER-example.csv', 'w', encoding='UTF8') as f:
f.write(csv_result)
print("A csv file is created and saved in the same folder of this notebook.")
Sentiment Classification
Sentiment Classification is a text analysis technique that aims to determine the sentiment or opinion expressed in a given piece of text. It involves classifying text into different sentiment categories such as positive, negative, or neutral.
Here is a quick example:
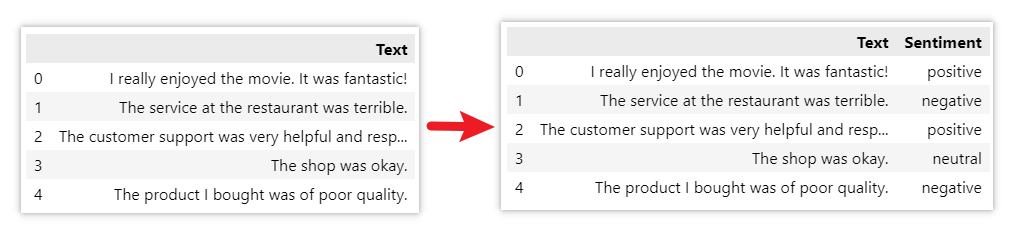
Below is the code for doing so:
import pandas as pd
# Create a sample DataFrame
sampledata = {
'Text': ["I really enjoyed the movie. It was fantastic!",
"The service at the restaurant was terrible.",
"The customer support was very helpful and responsive.",
"The shop was okay.",
"The product I bought was of poor quality."]
}
df = pd.DataFrame(data=sampledata)
df# Define the instruction for sentiment analysis
instruction = "Please analyze the sentiment of the following text. Only use the exact wording 'positive', 'negative', or 'neutral' in your response. Do not say any other irrelevant things, no punctuation."
# Create a new column for sentiment
df['Sentiment'] = ""
# Iterate over each row in the DataFrame
for index, row in df.iterrows():
# Get the text from the 'Text' column
text = row['Text']
# Get the sentiment response using the get_response function
sentiment = get_response(text, instruction)
# Store the sentiment result in the 'Sentiment' column
df.at[index, 'Sentiment'] = sentiment
# display the updated DataFrame
dfSemantic Search
Furthermore, LLMs can also extend their classification abilities beyond general sentiment. For example, in addition to determining positive or negative sentiment, LLMs can classify text into different aspects or categories.
Let’s use the comments that we received in Library Services Quality Survey 2019 (LibQUAL+®) as example to see if LLMs can classify them into these categories: ‘Services’, ‘Facilities’, ‘Resources’, ‘Activities’ or ‘Cannot be classified’.

In this example, the power of the LLMs becomes apparent as it demonstrates its ability to perform semantic search. Even though the specific word facilities is not present in the given text I love the ground floor of the library, i think especially in the morning it is so peaceful and calm. (the third comment in the example), it can still recognize the underlying concept and match it to the category of “facilities”.
This highlights the strength of LLMs in understanding the meaning and context of the text, enabling it to perform searches based on semantic relevance rather than relying solely on exact keyword matches.
Below is the code for doing so:
# Use the comments that the library received in LibQUAL 2019 as sample data https://library.hkust.edu.hk/about-us/user-engagement/libqual2019/
sampledata = {
'Text': ["The best place to stay in UST.",
"Our library is the best!",
"I love the ground floor of the library, i think especially in the morning it is so peaceful and calm.",
"Our library provide information and resources for us, including materials and many classes about how to use them. I really thanks staffs of library. And further I hope that our library could provide more chance and resource of 3D printer and I really love it.",
"服務良好、環境非常舒適,可以讓我專心溫習、 資源豐富、職員亦很友善,樂意詳細回答我的問 題,活動種類繁多,可以讓我找到興趣,又能學習 新的東西。",
"图书馆有很好的环境,也会提供各种活动和讲座帮助我们熟悉使用图书馆的资源,喜欢我们的图书馆。"]
}
libqual2019 = pd.DataFrame(data=sampledata)
libqual2019# Define the instruction for sentiment analysis
instruction1 = "Please analyze the sentiment of the following text. Only use the exact wording 'positive', 'negative', or 'neutral' in your response. All lowercase. Do not say any other irrelevant things. Do not include full stop in your response."
# Define the instruction for category classification
instruction2 = """
Please classify the following text into these categories (exact wordings) 'Services', 'Facilities', 'Resources', 'Activities' or 'Cannot be classified' in your response. Do not say any other words. Remember only use these 4 categories in your response: 'Services', 'Facilities', 'Resources', 'Activities', 'Cannot be classified'. Use 'Cannot be classified' only when no categories can be assigned to the text.
"""
# Create new columns for sentiment and category
libqual2019['Sentiment'] = ""
libqual2019['Category'] = ""
# Iterate over each row in the DataFrame
for index, row in df.iterrows():
# Get the text from the 'Text' column
text = row['Text']
# Get the response using the get_response function
sentiment = get_response(text, instruction1)
category = get_response(text, instruction2)
# Store the result in the column
libqual2019.at[index, 'Sentiment'] = sentiment
libqual2019.at[index, 'Category'] = category
# display the updated DataFrame
libqual2019Language Translation
LLMs can also be effectively utilized for language translation tasks, including the conversion of classical Chinese (文言文) to vernacular Chinese (白話文).
Many classical texts, such as ancient philosophical works, historical records and literary masterpieces, hold significant cultural and intellectual importance. However, their language structures and expressions can make them challenging to comprehend for contemporary readers. By employing LLMs for translation, these texts can be rendered into vernacular language, making them more accessible and easier to understand for a wider audience.
Let’s use some of the text in《九章算術》(The Nine Chapters on the Mathematical Art) as example. This book is one of the earliest Chinese mathematics books, written during the period from the 10th to the 2nd century BCE.
instruction = "You are an expert in Mathematics and proficient in classical Chinese."
Text = """
今有田廣十五步,從十六步。問為田幾何?
答曰:一畝。
方田:又有田廣十二步,從十四步。問為田幾何?
答曰:一百六十八步。
方田術曰:廣從步數相乘得積步。以畝法二百四十步除之,即畝數。百畝為一頃。
"""
get_response(f"""
請把以下文言文翻譯成白話文:
文言文:{Text}
""",
instruction)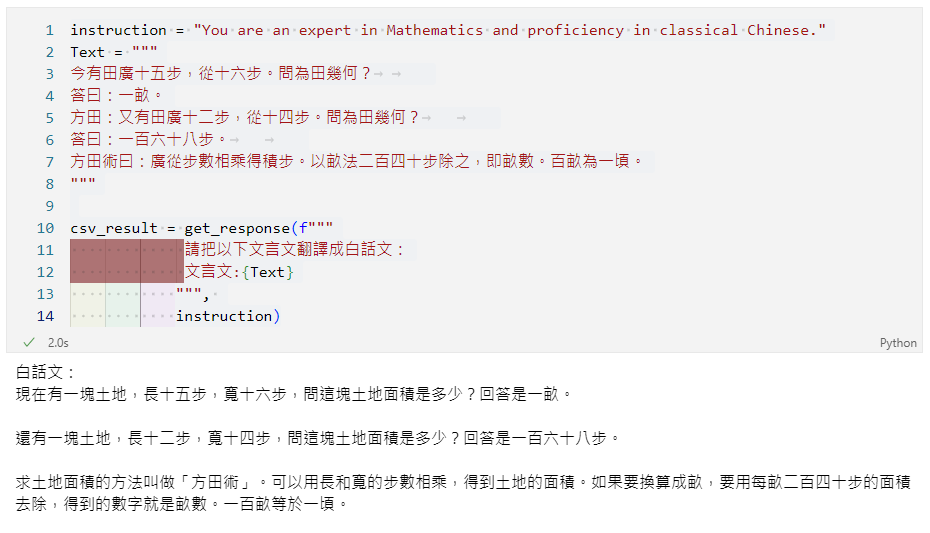
instruction = "You are an expert in Mathematics and proficient in classical Chinese."
Text = """
今有田廣十五步,從十六步。問為田幾何?
答曰:一畝。
方田:又有田廣十二步,從十四步。問為田幾何?
答曰:一百六十八步。
方田術曰:廣從步數相乘得積步。以畝法二百四十步除之,即畝數。百畝為一頃。
"""
get_response(f"""
請以數學公式逐步解釋以下文言文的內容:
文言文:{Text}
""",
instruction)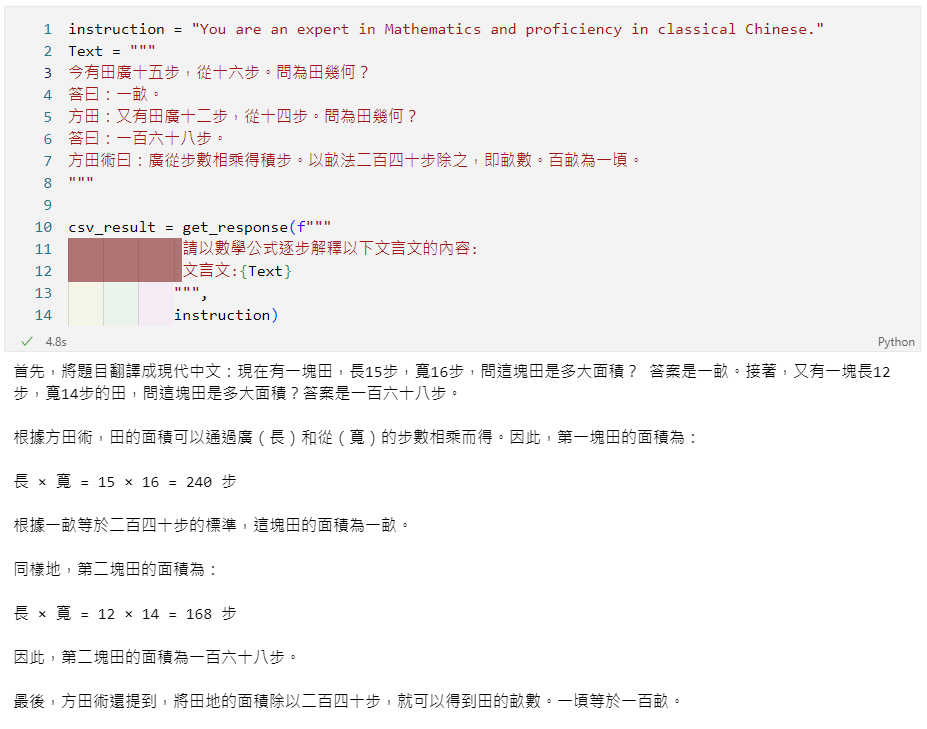
Challenge For You
We believe that you have now gained a deeper understanding of the capabilities and applications of LLMs. To challenge your newfound skills, we have prepared a dataset for you to practice on. This dataset contains information about some scientific illustrations from our rare books with detailed descriptions. You can download the dataset from our GitHub repository.
Now, it’s time to put your skills to the test. Let’s see if you can add the following new columns to the dataset:
- Language of title: indicate the language of the title, e.g. English, Latin, etc.
- Title (in English): translate the non-English titles into English.
- Short Biography of the Author: Extract information about the author from the description column in the dataset.
- Illustration Description (within 30 words): Summarize the text in descriptions while retaining the essential information about the illustration.
- Keywords: Provide 5 terms that capture the essence of the illustration.
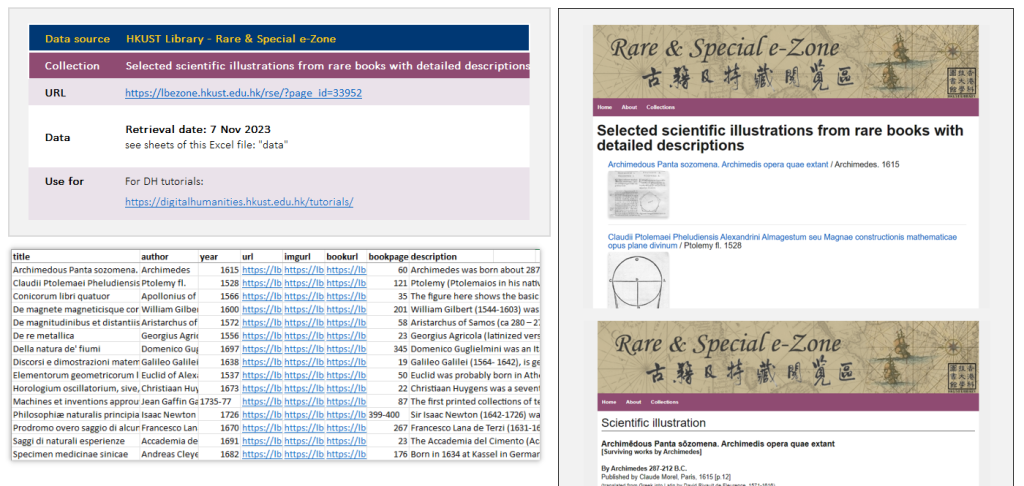
https://lbezone.hkust.edu.hk/rse/?page_id=33952
Download the dataset here
Recommended resources
We highly recommend you to watch the videos of the short courses of “Learn Generative AI” series offered by DeepLearning.AI. They are available online for free. They offer a learning experience where notebooks and videos are presented side by side. You can execute the code in real-time alongside the provided notebooks, enabling a hands-on learning experience that reinforces your understanding of the concepts about generative AI effectively.
Conclusion
The use cases mentioned in this article represent just a few examples of the vast possibilities that arise from utilizing the OpenAI API key. The potential applications extend far beyond what has been covered. If you have any other specific areas of interest or unique use cases in mind, feel free to share them with us!
Additionally, if you have ideas but unsure how to implement them, we welcome you to reach out to us. We would be delighted to engage in discussions and explore possibilities together.
– By Holly Chan, Library
November 16, 2023
You may also be interested in…