Tracing Scholars’ Digital Identities: An Automatic System for Multisource Verification and Extraction
Digital Humanities Student Project (Fall 2025)
This project is a course project for HUMA5630 Digital Humanities

This is the group photo of the first China–United States Biochemistry Examination and Application (CUSBEA) cohort. The program had 418 students in total. For this course project, we chose CUSBEA alumni working in academia (one-third of the total) as our case study subjects for the algorithm application. Among them, 50 are academicians or fellows of the American Association for the Advancement of Science (AAAS).
About This Project
This group project is driven by an ongoing research project, which studies 1831 post-tertiary Chinese students enrolled in China-US PhD Examination and Application (CUS-PhD-EA), from 1979 to 1989. This group is significant because they contributed significantly to China and the US academe as well as major scientific, technological, and especially pharmaceutical companies in the US and Europe.
In order to accurately trace, verify, and quantify the academic achievements of these scholars, we tried to integrate multiple data sources, including Web of Science, Google Scholar, Scopus etc., so as to collect their complete publication records, citation counts, and H-index, using our CUSD-CPEA[1] database as the core reference to resolve identity ambiguity and build complete, verified individual profiles.
Retrieving scholars’ complete academic records is challenging due to two main reasons: identical or similar names among scholars, especially in the US, and fragmented profiles on academic platforms. This makes manually collecting and checking full publication records very time-consuming. Therefore, we propose an automated system to help us verify and extract scholars’ digital identities from multiple sources.
[1] The CUSD-CPEA dataset includes all CUS-PhD-EA alumni’s basic information, educational, and occupational background. Link to the dataset
The Pipeline
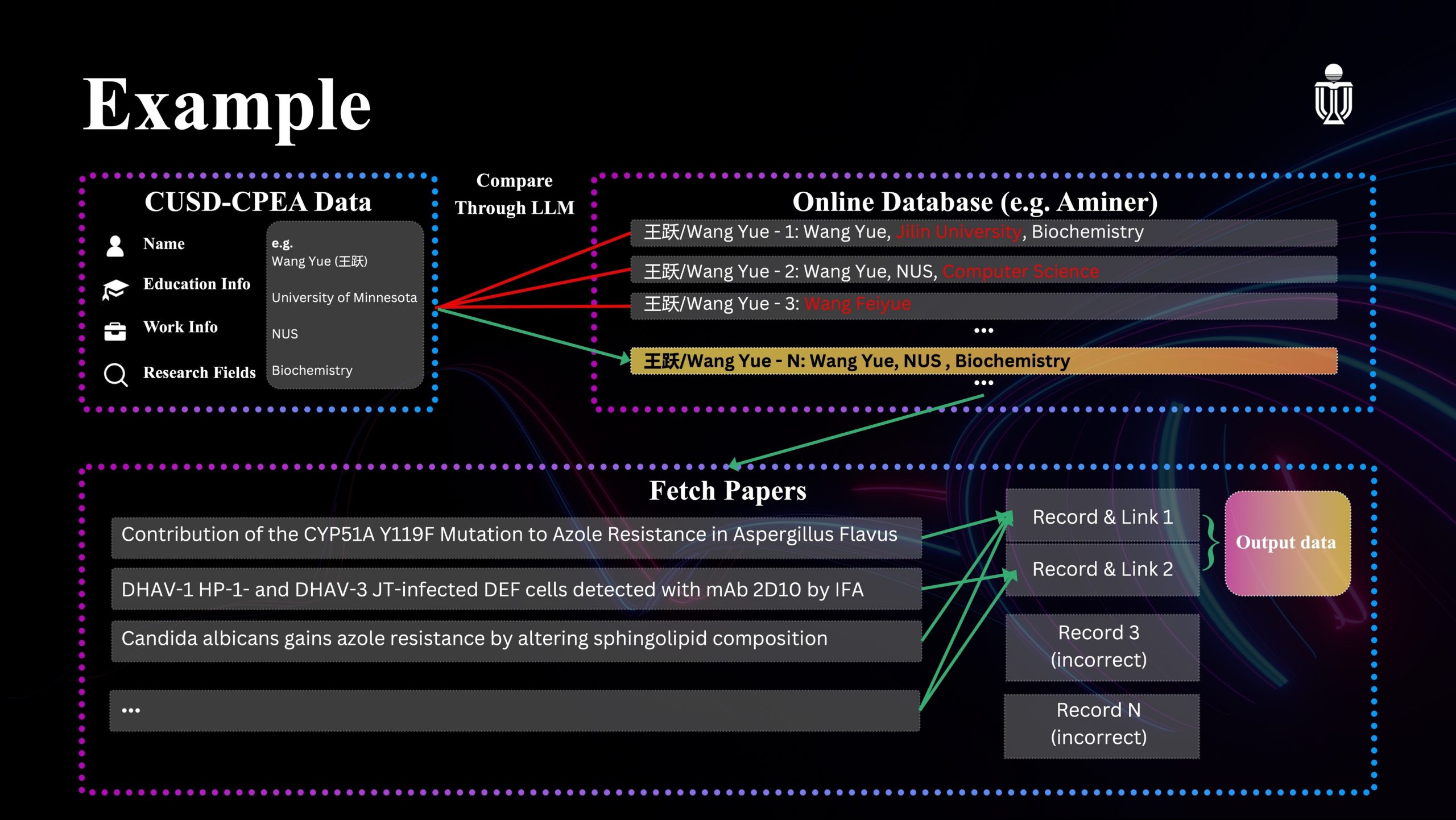
First, we extract basic personal information from the CUSD-CPEA data, including name, education, work experience, and research interests. Second, we use the AMiner public API to identify the correct alumni we want to find. After that, we extract their high-citation papers and identify their multiple profile pages in Web of Science. Finally, we manually export the data for further analysis. An example for Professor Wang Yue can be seen in Figure 1.
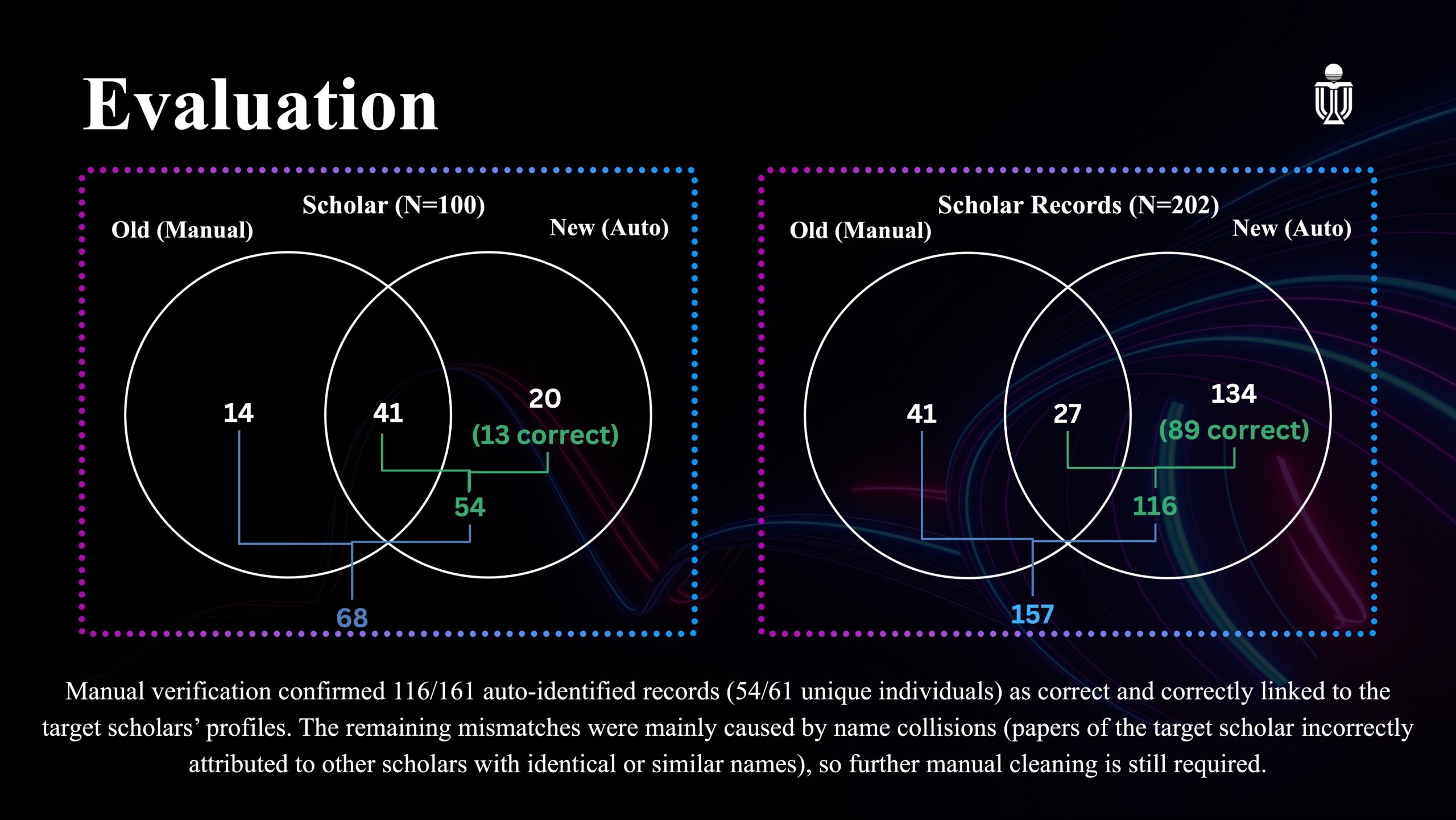
We draw two Venn diagrams in Figure 2 to show our results. The left one shows the individual level data and the right one for records level. For the randomly sampled 100 alumni, the system find 61 people, among which 54 is correct. As for records, our system finds 161 records in total, in which 116 are correct. This automated and light manual workflow nearly doubled the number of verifiable records.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
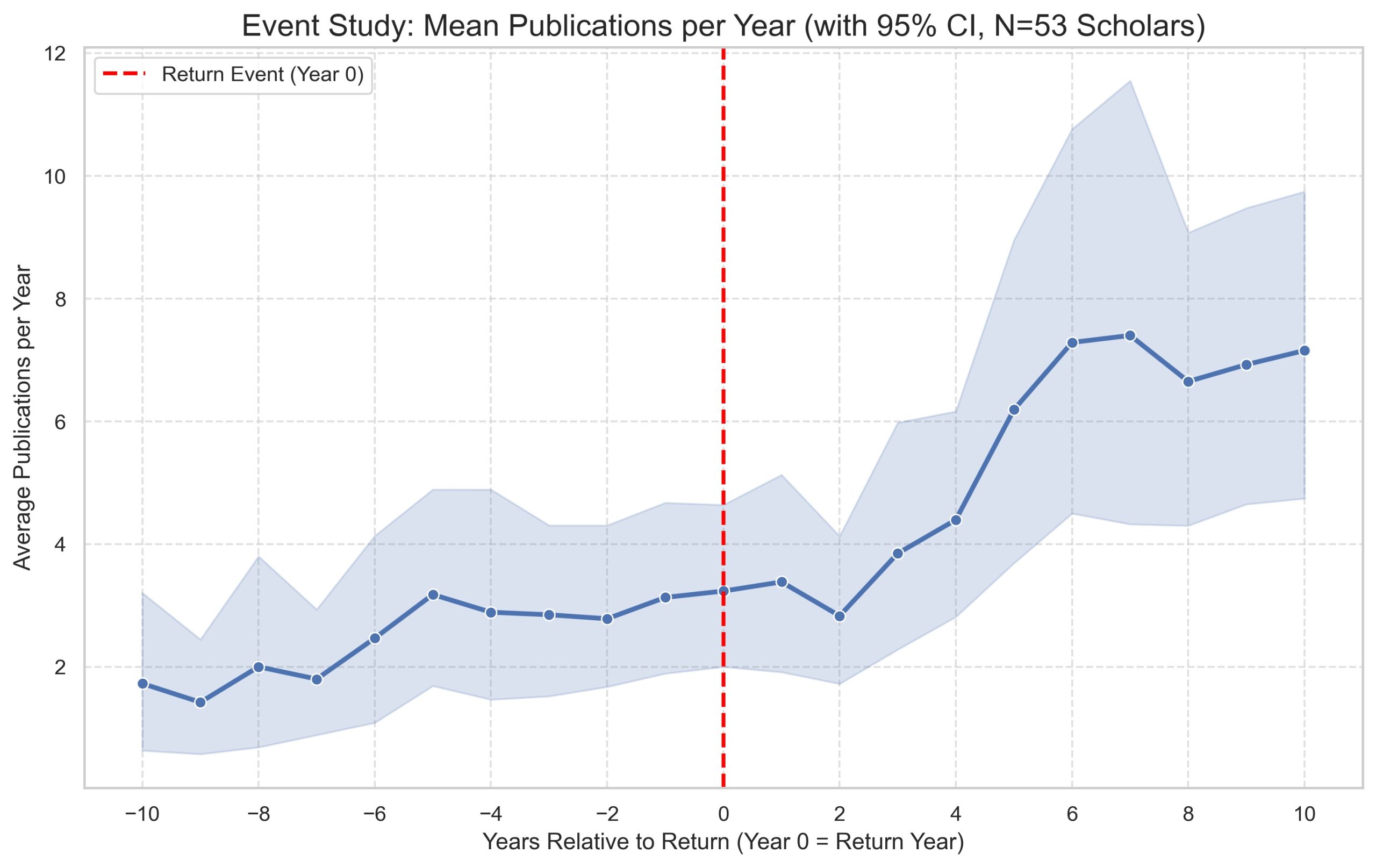
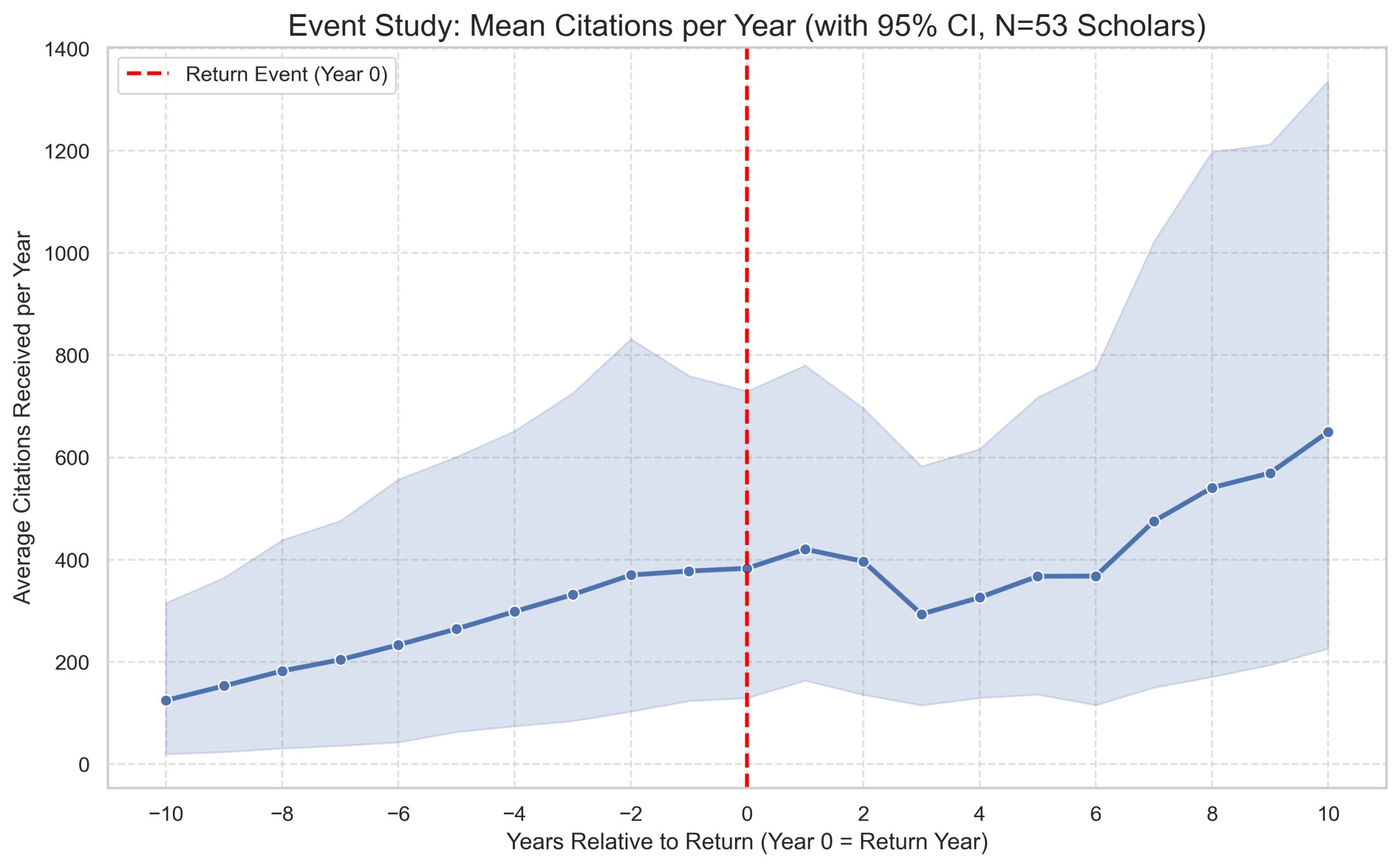
Figure 3: Average publication and citation trends relative to the year of return
Note: N=53, for those who has indicated clear coming back year
{kind=link}
{kind=link}
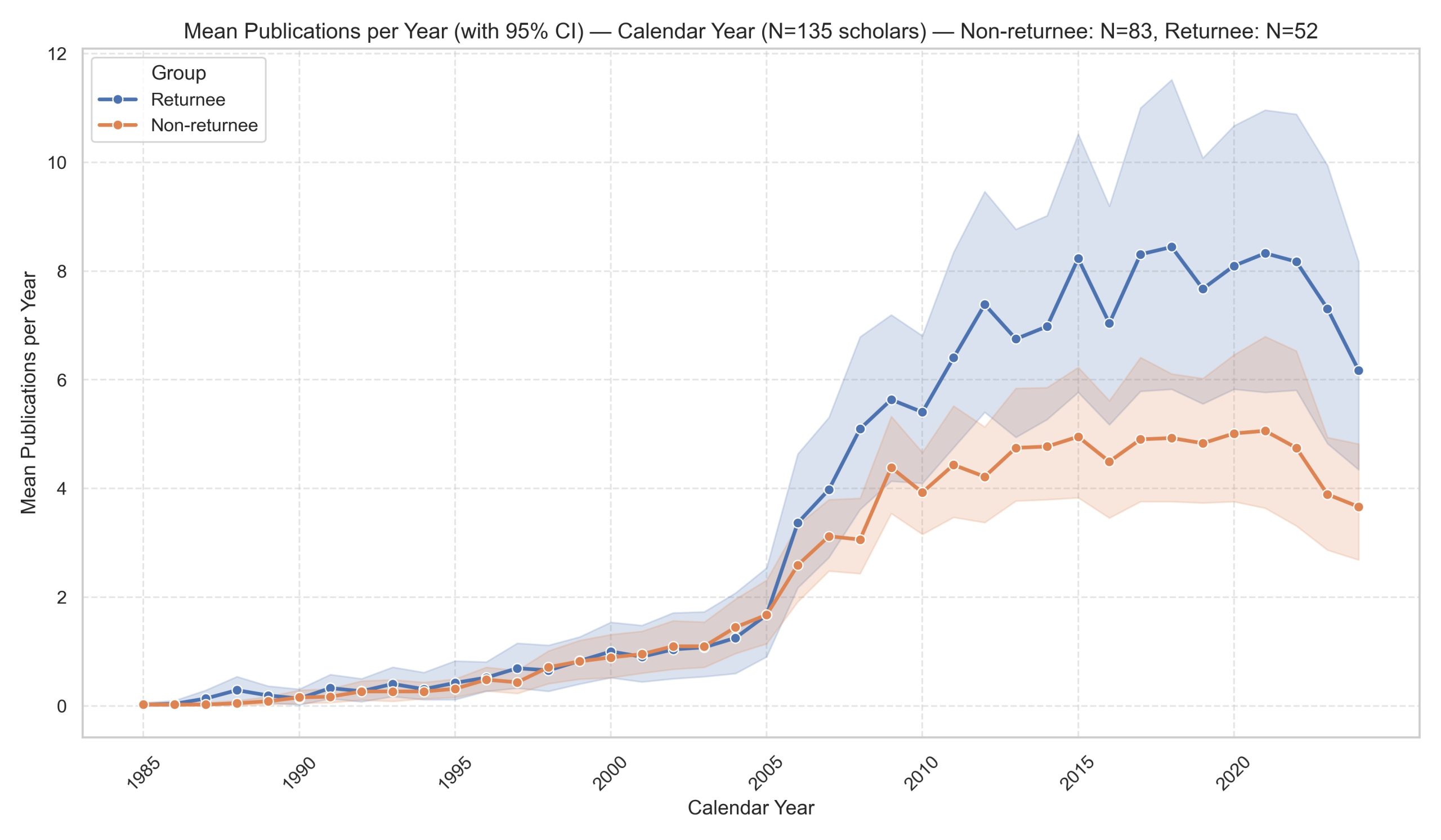
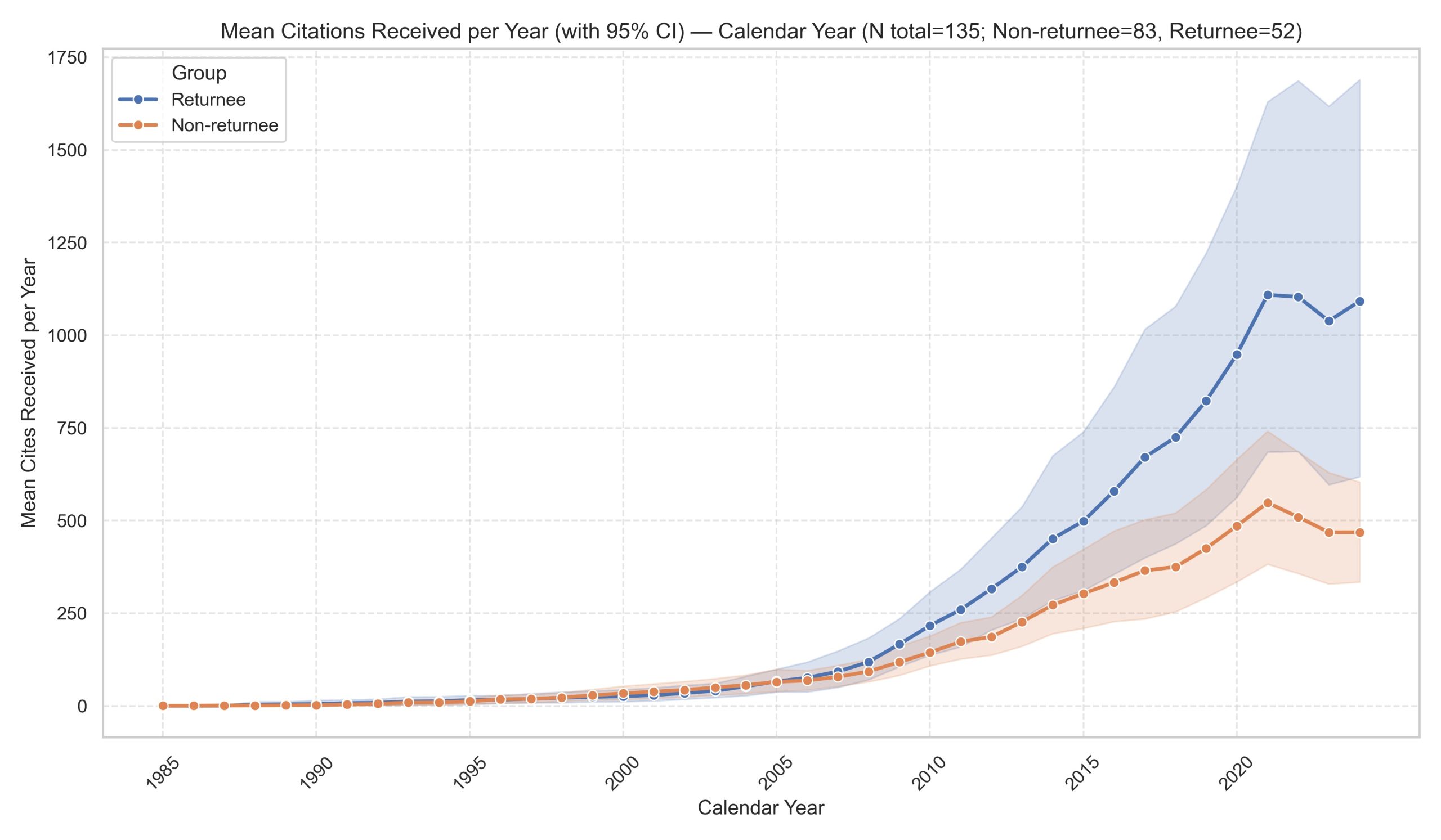
Figure 4: Average publication and citation trends: Returnees V.S. Non-Returnees Alumni
{kind=link}
{kind=link}
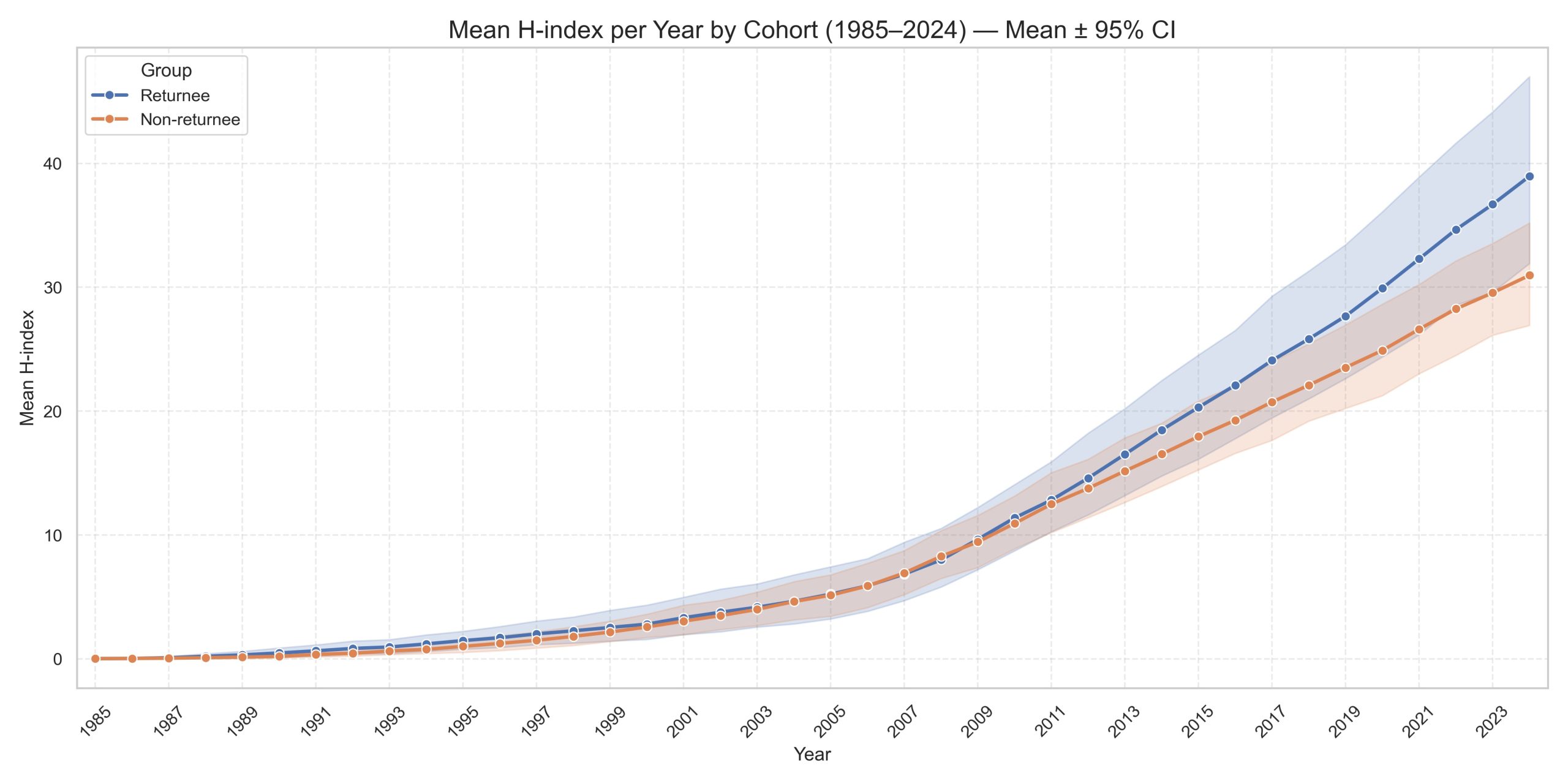
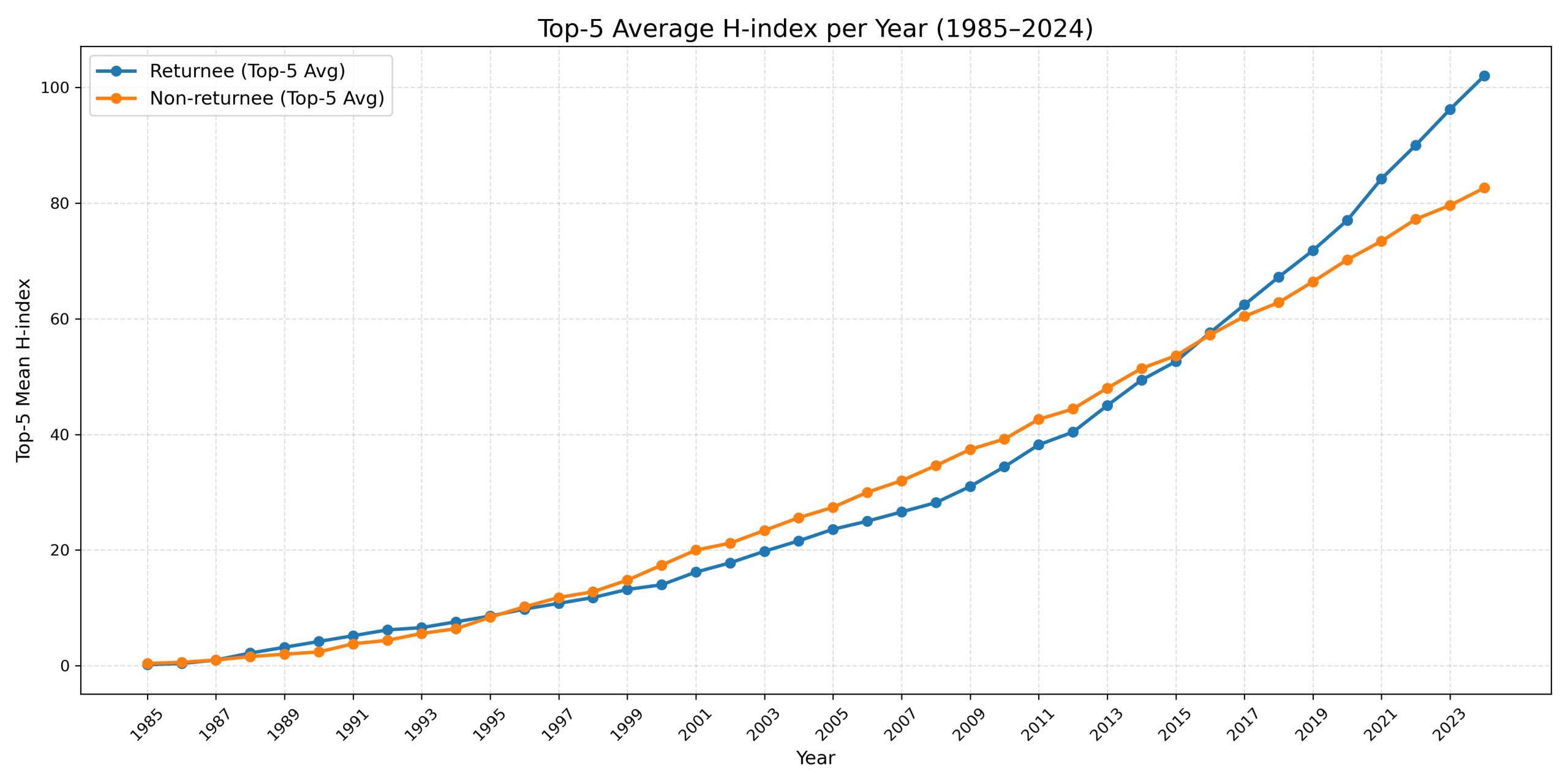
Figure 5: Average H-index trends: Returnees V.S. Non-Returnees Alumni
Key Findings
With the new dataset, we conducted a preliminary analysis focusing on CUS-PhD-EA alumni in the field of biochemistry, comparing returnees and non-returnees. Our main findings are (Figure 3-5): First, the publication and citation per year showed a decline within one to two years after returning to China, but then resumed a growth trend afterwards;
Second, since 2005, the cohort of returned alumni has consistently outpaced non-returnees in yearly publications and citations;
Third, in the early years, the two groups showed little difference, but over time, the returned scholars steadily widened their lead in both overall and top-tier academic output.
Platforms like Web of Science often mix up papers from scholars with the same name, leading to incorrect attributions. Our algorithm efficiently locates accurate scholar profiles, yet manual verification remains necessary for full accuracy. Future work will expand data sources to include personal homepages and CVs, and refine prompts, judgment, and retrieval strategies.
Limitations
Platforms like Web of Science often mix up papers from scholars with the same name (e.g., an alumnus’s profile wrongly includes publications by a namesake, or their own papers end up credited to someone else’s profile).
Our algorithm can effectively flag these errors, but ultimate accuracy still requires manual verification.
{kind=link}
{kind=link}
Dongqian Liu
PhD Humanities
Ao Jiang
MSc Global China Studies
Yihang Jiang
PhD Individual Interdisci Prog
GitHub Repository
Please find the detailed code and project documentation at the link below.