The Application of NER Models in the Literature Field
Digital Humanities Student Project (Fall 2025)
This project is a course project for HUMA5630 Digital Humanities

Book cover of Blossoms by Jin Yucheng
About This Project
- Our project means to build a NER model for modern and contemporary Chinese literature. Which used to explore the value of NER in assisting literary research.
- Given a Chinese text as input, the expectation is for the model to scan each word in the text and identify the entities within it (such as people, places, concepts, times, etc.). This is an entity recognition (NER) task.
Possible Uses: Geocriticism
- A spatial criticism methods of literary texts.
- The interdisciplinary product combining Chinese literature and geography studies.
- We can use NER to assist in identifying geographical names in literature, thereby constructing the geographical space of a specific literature and understanding the literary memories of that place.
CRF Model
- The full name of CRF is Conditional Random Fields (CRF), which is a probabilistic graphical model used for tagging and segmenting sequential data. It belongs to a discriminative model, meaning it directly models the conditional probability of the output tagging sequence given the input sequence, without modeling the overall distribution of the input.
- In simple terms, CRF assigns the most reasonable label to each position by considering the dependency between consecutive labels.
BERT Model
BERT-Tiny
- Using the open-source model at https://huggingface.co/ckiplab/bert-tiny-chinese-ner, this model is fine-tuned from BERT-Tiny Chinese by CKIP Lab and supports Traditional Chinese.
- Basic information of the Bert model: 12M, 4 layers, hidden layer dimension size of 312;
- Additional classification layer: 312 dimensions -> 73 dimensions, classifying tokens into 73 entity labels.
BERT-Base
- Using the open-source model at https://huggingface.co/ckiplab/bert-base-chinese-ner, which was fine-tuned by CKIP Lab based on BERT Base Chinese and supports Traditional Chinese.
- Basic information of the Bert model: 110M, 12 layers, hidden layer dimension size of 768;
- Additional classification layer: 768 dimensions -> 73 dimensions, classifying tokens into 73 entity labels.
Result Comparing
- Training environment for the CRF model (using CPU): Intel(R) Core(TM) i5-9300H CPU @ 2.40GHz (8G)
- Fine-tuning environment for the bert-tiny and bert-base models (using GPU): NVIDIA GeForce RTX 4090 (24G)
- Number of training sets: Approximately 4800 sentences, totaling 1 million lines
Token
| Index\Model | CRF | bert-tiny | bert-base |
| Accuracy | 0.8526 | 0.8698 | 0.8939 |
| Precision | 0.5619 | 0.5648 | 0.6299 |
| Recall | 0.4883 | 0.5248 | 0.6024 |
| F1-Score | 0.5156 | 0.5420 | 0.6011 |
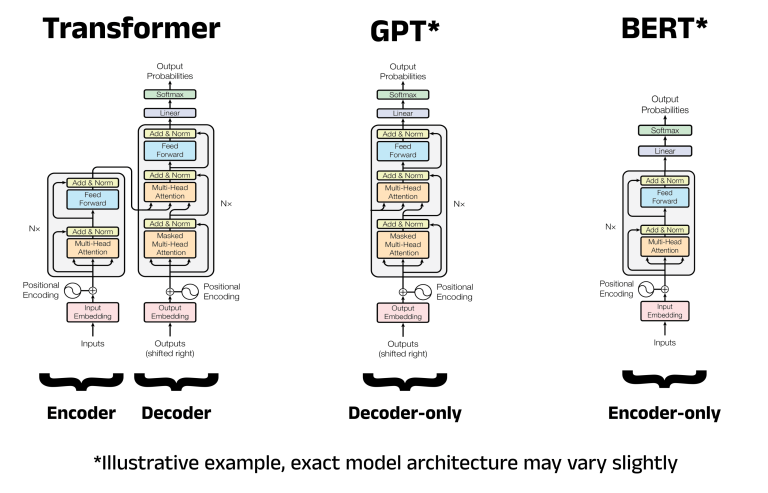
A comparison of the architectures for the Transformer, GPT, and BERT. Image adapted by author from the Transformer architecture diagram in the “Attention is All You Need” paper
Entity
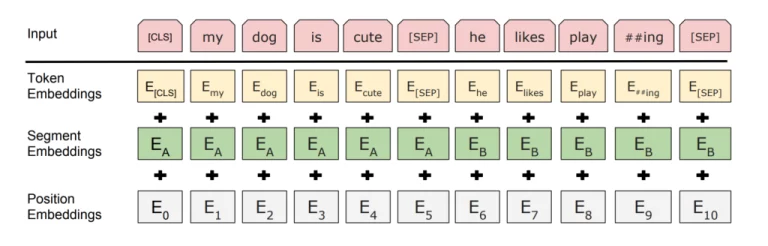
An overview of the BERT embedding process. Image taken from the BERT paper
| Index\Model | CRF | bert-tiny | bert-base |
| Accuracy | 0.8526 | 0.8698 | 0.8939 |
| Precision | 0.6926 | 0.6037 | 0.6908 |
| Recall | 0.6049 | 0.6370 | 0.7242 |
| F1-Score | 0.6458 | 0.6199 | 0.7071 |
Practical Uses
By using NER, we can make the construction of geographical space in literature more precise and systematic.
For example, we can achieve automatic extraction of entities: quickly identify place names such as “lan“, “Cao Yang New Village“, and “Suzhou River” in the text, avoiding omissions in manual annotation.
We can also construct a spatial relationship network: by identifying the co-occurrence relationships of place names (such as the frequent co-occurrence of “Huaihai Road” and “Guo Tai Cinema“), we can reveal the spatial differentiation between “Shang Zigu” (Luwan District) and “Xia Zigu” (Huaxi District) in Shanghai, assisting in the hierarchical spatial analysis in the “geography and literature” dimension.
By analyzing the frequently occurring place names in the literature of a certain region (such as “Jiuzhou” and “Xiguan” in Guangzhou, and “Teahouse” and “Jinli” in Chengdu), the “literary landmarks” of that city can be extracted, providing materials for the construction of local cultural brands (such as using “Biancheng” as the literary IP of Xiangxi’s tourism and culture).
Specific examples: “Yan Food Diary” and “Like a Seal and a Jade” were both published in recent years. Both focus on the urban literature of Lingnan. Through NER entity recognition, it was found that both in writing about Lingnan, there were repeatedly occurring place names, such as “Jiuzhou” appeared in both of their literary works.
WU Wen-shin
MA Chinese Culture
LIANG Xiaojing
MA Chinese Culture
LI Jialu
MA Social Science
TSOI Sin Yu
MA Chinese Culture
GitHub Repository
Please find the detailed code and project documentation at the link below.